PaLM

منظور از B در اعداد بالا مترادف Billion در زبان انگلیسی و به معنای میلیارد است.
PaLM (Pathways Language Model)
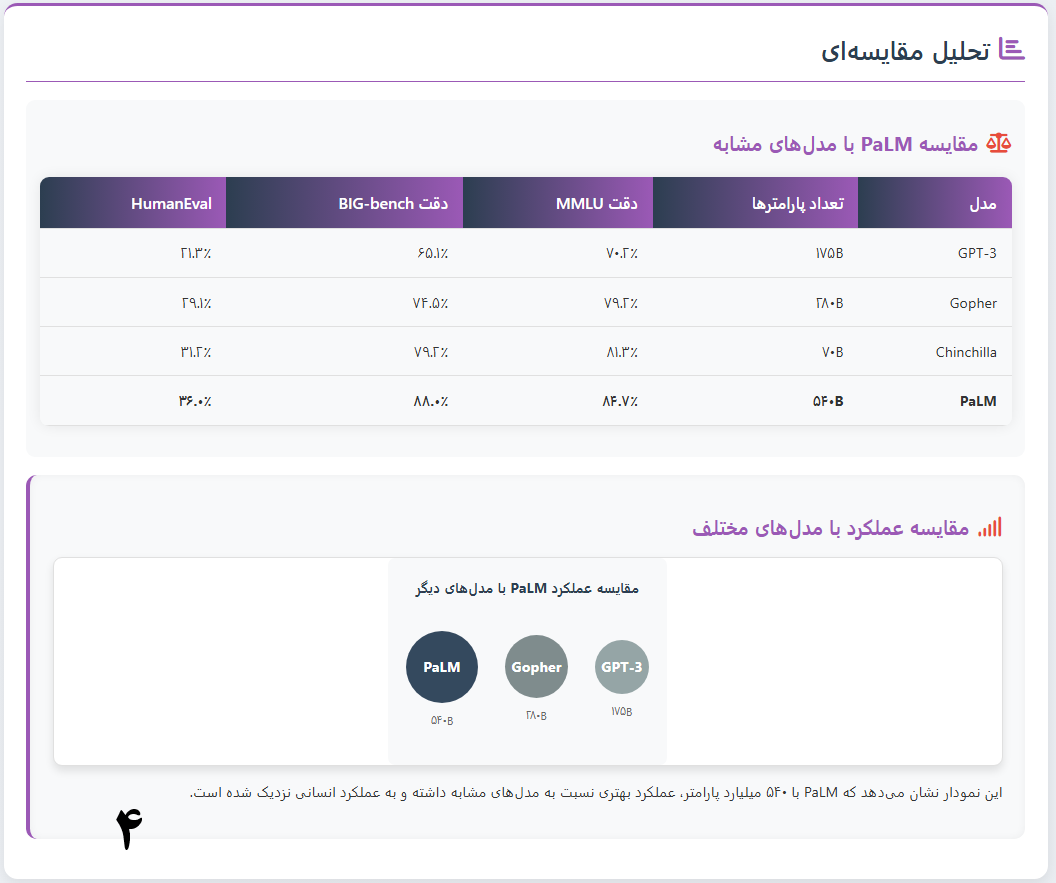
مدل زبان مسیرها (PaLM) یک مدل زبان بزرگ (LLM) مبتنی بر مبدل و رمزگشای متراکم ۵۴۰ میلیارد پارامتری است که توسط هوش مصنوعی گوگل توسعه داده شده است.
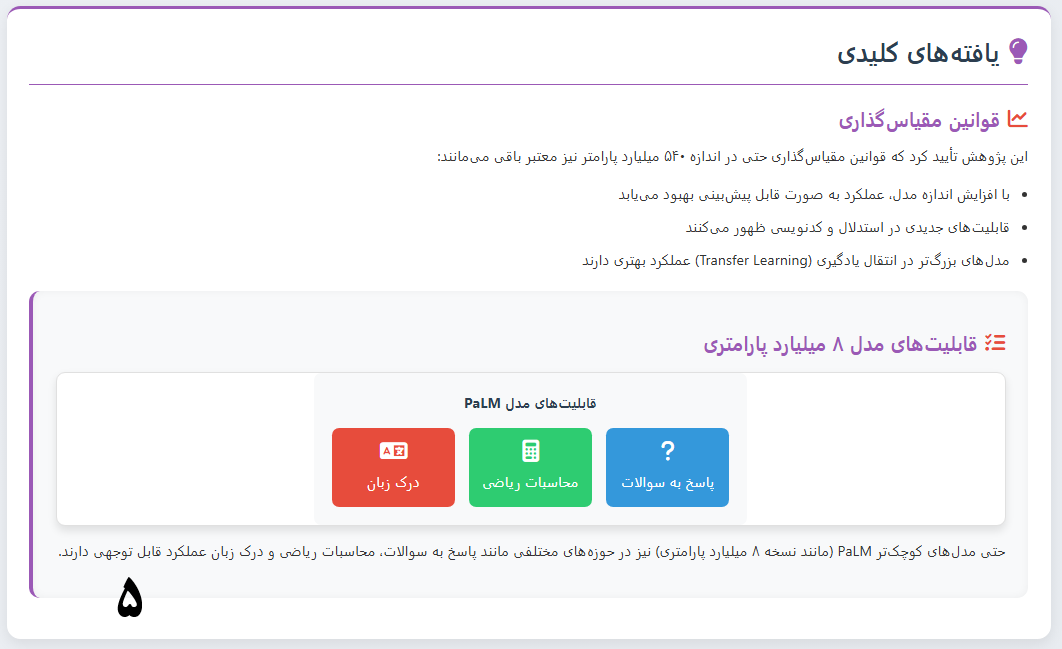
محققان همچنین نسخههای کوچکتری از PaLM (با ۸ و ۶۲ میلیارد پارامتر) را برای آزمایش اثرات مقیاس مدل آموزش دادند.
PaLM قادر به انجام طیف گستردهای از وظایف، از جمله استدلال عقل سلیم، استدلال حسابی، توضیح شوخی، تولید کد و ترجمه است.
PaLM هنگامی که با زنجیره فکری ترکیب شد، عملکرد بسیار بهتری در مجموعه دادههایی که نیاز به استدلال چند مرحلهای داشتند، مانند مسائل کلامی و سوالات مبتنی بر منطق، به دست آورد.
این مدل برای اولین بار در آوریل ۲۰۲۲ اعلام شد و تا مارس ۲۰۲۳، زمانی که گوگل یک API برای PaLM و چندین فناوری دیگر راهاندازی کرد، خصوصی باقی ماند.
این API در ابتدا برای تعداد محدودی از توسعهدهندگان که قبل از انتشار عمومی به لیست انتظار پیوستند، در دسترس بود.
گوگل و دیپمایند نسخهای از PaLM 540B (با ۵۴۰ میلیارد پارامتر) به نام Med-PaLM را توسعه دادند که بر اساس دادههای پزشکی تنظیم دقیق شده و در معیارهای پاسخ به سوالات پزشکی از مدلهای قبلی بهتر عمل میکند.
Med-PaLM اولین مدلی بود که در سوالات مجوز پزشکی ایالات متحده نمره قبولی گرفت و علاوه بر پاسخ دقیق به سوالات چندگزینهای و تشریحی، استدلال ارائه میدهد و قادر به ارزیابی پاسخهای خود است.
گوگل همچنین PaLM را با استفاده از یک مبدل بینایی برای ایجاد PaLM-E، یک مدل زبان بینایی که میتواند برای دستکاری رباتیک بدون نیاز به آموزش مجدد یا تنظیم دقیق استفاده شود، گسترش داد.
در ماه مه ۲۰۲۳، گوگل PaLM 2 را در سخنرانی سالانه Google I/O معرفی کرد.
گزارش شده است که PaLM 2 یک مدل ۳۴۰ میلیارد پارامتری است که بر روی ۳.۶ تریلیون توکن آموزش دیده است.
در ژوئن ۲۰۲۳، گوگل AudioPaLM را برای ترجمه گفتار به گفتار معرفی کرد که از معماری و مقداردهی اولیه PaLM-2 استفاده میکند.

ترنسفورمر چیست؟
ترنسفورمر یا مُبَدِّل، روشی است که به رایانه اجازه میدهد تا یک دنباله از نویسهها را به دنباله دیگری از نویسهها تبدیل کند. این روش میتواند برای مثال برای ترجمه متن از یک زبان به زبان دیگر استفاده شود. برای این کار، ترانسفورمور با استفاده از یادگیری ماشین بر روی مجموعه بزرگی از دادههای نمونه آموزش داده میشود و سپس مدل آموزشدیده برای ترجمه استفاده میشود.
برای اطلاعات بیشتر می توانید به لینک روبرو مراجعه کنید: همه چیز درباره ترنسفورمر
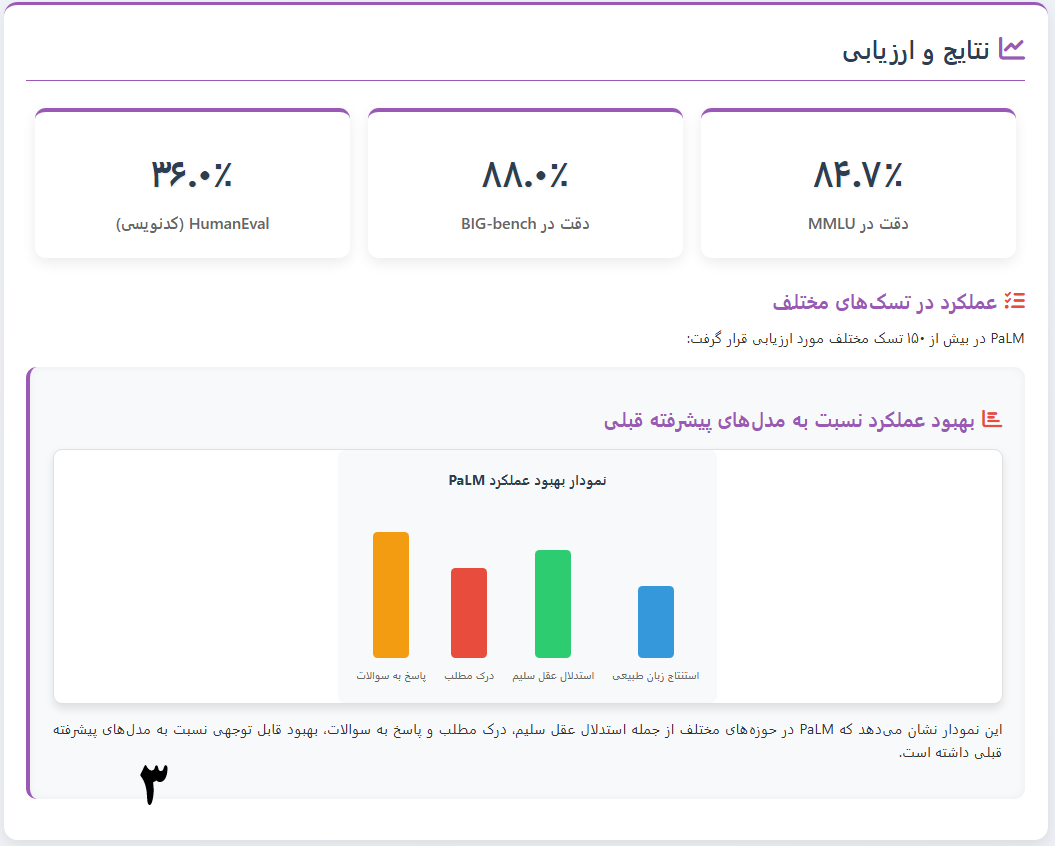
منظور از دقت در MLU و Big-Bench و HumanEval چیست؟
ارزیابی مدلهای زبانی بزرگ (LLM) و بنچمارکها
معیارهای ارزیابی مدلهای زبانی بزرگ
مدلهای زبانی بزرگ (LLMها) بسیار پیچیده هستند و استفاده از معیارهای ساده مانند امتیاز ROUGE و امتیاز BLEU تنها اطلاعات محدودی درباره قابلیتهای مدل ارائه میدهند. برای ارزیابی دقیقتر، میتوانید از بنچمارکهای پیشرفته استفاده کنید که توسط محققان برای این منظور طراحی شدهاند.
اهمیت انتخاب مجموعه دادههای ارزیابی مناسب
انتخاب مجموعه داده ارزیابی مناسب یکی از مهمترین مراحل ارزیابی مدلهای زبانی است. مجموعه دادههایی که مهارتهای خاص مدل مانند استدلال یا دانش عمومی را بررسی میکنند، درک بهتری از تواناییهای مدل ارائه میدهند. همچنین مجموعه دادههایی که بر خطرات بالقوه مانند اطلاعات نادرست یا نقض حق نشر تمرکز دارند، بسیار مفید هستند.
موضوعی که باید در نظر داشته باشید این است که آیا دادههای ارزیابی در طول آموزش مدل دیده شدهاند یا خیر. ارزیابی مدل روی دادههای جدید به شما کمک میکند تا به نتایج دقیقتری برسید.
آشنایی با بنچمارکهای کلیدی برای ارزیابی مدلهای زبانی
در این بخش به معرفی بنچمارکهای مهمی مانند GLUE، SuperGLUE، HELM، MMLU و BIG-bench میپردازیم که برای ارزیابی دقیق مدلهای زبانی طراحی شدهاند.
GLUE: ارزیابی درک زبان عمومی
GLUE یکی از قدیمیترین بنچمارکها است که در سال ۲۰۱۸ معرفی شد. این ابزار شامل وظایف زبان طبیعی مانند تحلیل احساسات و پاسخگویی به سؤالات است. هدف اصلی این بنچمارک، تشویق توسعه مدلهایی است که بتوانند در وظایف متنوع به خوبی عمل کنند.
برای اطلاعات بیشتر، میتوانید به صفحه GLUE مراجعه کنید.
SuperGLUE: جانشین پیشرفته GLUE
SuperGLUE در سال ۲۰۱۹ معرفی شد و شامل وظایف چالشبرانگیزتری است که در نسخه قبلی وجود نداشتند. این بنچمارک وظایفی مانند استدلال چند جملهای و درک مطلب را شامل میشود. برای مشاهده عملکرد مدلها، میتوانید به وبسایت SuperGLUE مراجعه کنید.
HELM: ارزیابی کلنگر مدلهای زبانی
HELM یکی از جدیدترین بنچمارکها است که بر شفافیت مدلها و ارائه راهنمایی در مورد عملکرد مدلها در وظایف خاص تمرکز دارد. این بنچمارک از معیارهای مختلفی مانند دقت، انصاف، تعصب و سمیت استفاده میکند تا ارزیابی کاملی از مدل ارائه دهد.
برای مشاهده نتایج، به صفحه نتایج HELM مراجعه کنید.
MMLU: درک زبان چندوظیفهای عظیم
MMLU برای مدلهای زبانی مدرن طراحی شده و وظایفی مانند ریاضیات ابتدایی، علوم کامپیوتر، حقوق و غیره را پوشش میدهد. این بنچمارک نیاز به دانش گسترده و توانایی حل مسئله دارد.
BIG-bench: چالشهای بزرگ برای مدلهای زبانی
BIG-bench شامل ۲۰۴ وظیفه است که موضوعاتی مانند زبانشناسی، ریاضیات، استدلال عقل سلیم و تعصب اجتماعی را شامل میشود. این بنچمارک به دلیل تنوع زیاد وظایف، یکی از چالشبرانگیزترین ابزارهای ارزیابی مدلهای زبانی است.
منبع: https://class.vision/